
If you have been building generative AI applications over the last few years, you are probably intimately familiar with Retrieval-Augmented Generation (RAG). For a long time, traditional RAG pipelines—powered by vector databases, text chunking, and mathematical embeddings were the absolute gold standard for giving Large Language Models (LLMs) external context.
However, as enterprise demands grow, traditional RAG is hitting an undeniable ceiling. Semantic “vibe matching” struggles with complex cross-references, and arbitrary text chunking often destroys context. Enter vectorless RAG with page index, a revolutionary framework that ditches embeddings entirely. By treating document retrieval as a reasoning exercise rather than a mathematical similarity game, this new approach is solving the biggest pain points of AI document analysis.
In this comprehensive guide, we will explore what vectorless RAG with page index is, analyze deep market insights from recent 2026 industry benchmarks, and provide a full step-by-step Python implementation guide.
What is Vectorless RAG with Page Index?
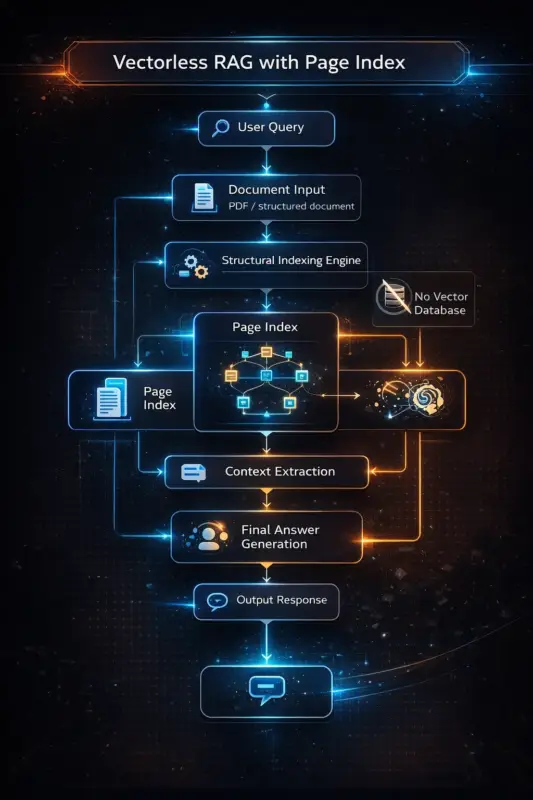
Vectorless RAG with page index is an advanced retrieval architecture (popularized by open-source frameworks like VectifyAI’s PageIndex) that uses a hierarchical, tree-structured “Table of Contents” instead of a vector database.
Instead of slicing a document into arbitrary 500-word chunks and mapping them into high-dimensional space, a vectorless approach preserves the natural structure of the document (chapters, headings, sections, and pages). When a user asks a question, the LLM actively reads the document’s index tree—much like a human expert checking a book’s table of contents—and logically reasons its way to the exact section containing the answer.
Traditional Vector RAG vs. Vectorless RAG

To understand why this is such a massive leap forward, we must look at the flaws in standard vector RAG:
- The Chunking Problem: Splitting a legal contract or financial report into fixed-size chunks destroys the logical flow. Important ideas spanning multiple paragraphs get severed.
- Semantic “Vibe” Matching: Vector databases retrieve chunks based on semantic similarity, not actual relevance. If a document says “Refer to Appendix B,” vector search misses it because those words share no semantic similarity with the actual contents of Appendix B.
- The “Black Box”: Traditional RAG lacks explainability. It is often impossible to trace exactly why a specific text chunk was retrieved.
(Curious about how different foundational models perform when fed complex document context? Check out our deep dive: Claude vs Gemini Document Analysis: Which Should You Use in 2026?).
How Vectorless RAG Works: The Two-Phase Architecture
Market research across recent engineering blogs highlights that vectorless RAG relies on a distinct two-phase pipeline:
- Phase 1: Structural Indexing (Building the Tree): The system reads the full document and uses an LLM to outline its boundaries. It builds a hierarchical JSON tree where each node represents a specific section (e.g., Chapter 2 > Section 2.1). No embeddings are generated.
- Phase 2: Reasoning-Based Traversal: When queried, the system feeds the user’s prompt and the document’s lightweight “Table of Contents” to the LLM. The LLM acts as a reasoning engine, scanning the summaries and predicting exactly which node holds the answer.
Python Implementation: Building Vectorless RAG Step-by-Step
Ready to build it yourself? Here is a production-ready implementation using the official pageindex Python library. First, ensure you have your prerequisites: pip install pageindex openai requests.
Block 1: Initialization and Setup
We start by importing our libraries and setting up our clients. Unlike traditional RAG, you won’t see Pinecone, Weaviate, or ChromaDB here—just our indexer and our LLM.
import os
import asyncio
import openai
from pageindex import PageIndexClientInitialize Clients
PAGEINDEX_API_KEY = "YOUR_PAGEINDEX_API_KEY"
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"
pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)
openai_client = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)- Explanation: We are initializing the
PageIndexClientwhich will handle the heavy lifting of parsing the PDF and building the structural JSON tree. TheOpenAIclient is used strictly as our reasoning engine later on.
Block 2: The LLM Helper Function
We need a clean, asynchronous function to handle our calls to the LLM.
Python
# Helper function for LLM reasoning
async def call_llm(prompt, model="gpt-5.2", temperature=0):
response = await openai_client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content.strip()
- Explanation: We set the
temperatureto 0 because document retrieval and Q&A require deterministic, factual responses. We do not want the model getting “creative” with financial or legal data.
Block 3: Phase 1 – Structural Indexing
Here is where the magic happens. We submit the document not to be chunked and embedded, but to be structurally analyzed.
Python
async def main():
# Submit Document for Tree Generation
pdf_path = "financial_report_2026.pdf"
print("Submitting document to PageIndex...")
# Generates the hierarchical structure instead of embeddings
submit_resp = pi_client.submit_document(pdf_path)
doc_id = submit_resp["doc_id"]
print(f"Document Indexed Successfully! Doc ID: {doc_id}")
print("Building reasoning tree...")
- Explanation: The
submit_documentmethod reads the PDF, identifies chapters, subheadings, and tables, and builds a lightweight JSON map of the document. It returns adoc_idthat we use for querying.
Block 4: Phase 2 – Reasoning and Retrieval
Now, instead of a vector similarity search, we ask the system to “navigate” the tree to find our answer.
Python
# Query the Document
user_query = "What was the revenue impact of the Q3 supply chain disruption?"
print(f"Querying: {user_query}")
# Traverses the tree, finds the relevant node, and extracts raw context
retrieval_result = pi_client.submit_query(doc_id=doc_id, query=user_query)
context = retrieval_result["extracted_text"]
- Explanation: Under the hood, this function passes the user’s query alongside the document’s generated “Table of Contents” to an LLM. The LLM determines which section contains the answer, and the system extracts only the raw text from that specific structural node.
Block 5: Final Generation
Finally, we inject the perfectly retrieved text into a strict prompt.
# Generate final answer from the precisely retrieved context
final_prompt = f"Answer the query based ONLY on the following context:\n\nContext: {context}\n\nQuery: {user_query}"
answer = await call_llm(final_prompt)
print("\n--- Final Answer ---")
print(answer)
# Run the async loop
if __name__ == "__main__":
asyncio.run(main())
- Explanation: Because the
contextvariable contains a perfectly intact, logically complete section of the document (rather than a randomly chopped 500-word block), the final LLM generation is incredibly accurate and completely immune to hallucinations.
Pros, Cons, and the “Hybrid” Future
Based on extensive market research across enterprise engineering deployments in 2026, here is the objective truth about vectorless RAG:
The Advantages
- Unmatched Accuracy on Structured Docs: Recent industry benchmarks show vectorless frameworks scoring upwards of 98.7% on FinanceBench—crushing traditional vector RAG (which typically hovers around 40-50%).
- Zero Hallucinations Through Precision: By drastically shrinking the context window down to only logically relevant sections, the LLM doesn’t get confused by “noise” from irrelevant pages.
- 100% Traceability: Vectorless RAG natively provides exact citations. Because the LLM navigates to a specific structural node, it tells you exactly which page and heading it pulled the information from.
The Drawbacks
- Higher Latency: Because the system makes multiple LLM calls to traverse the tree, it takes a few seconds longer than a millisecond vector lookup.
- Cost at Scale: Relying on LLM reasoning for retrieval is computationally more expensive per query than a simple embedding similarity search.
The Verdict: Hybrid is King
The consensus among leading AI engineers is that the future is hybrid. Use fast, cheap vector databases to filter through 10,000 documents to find the right one, and then hand that document off to a vectorless RAG with page index system for deep, flawless, reasoning-based extraction.
The AI boom is refining how machines understand human intent across all domains. Just as document parsing has become more logical, AI visual synthesis has evolved past prompt-guessing into highly controllable artistry. If you are looking to master the visual side of the AI revolution, be sure to read our comprehensive guide on How to Generate Stunning AI Images in 2026: Complete Guide.
Conclusion
The era of “vibe-based” semantic retrieval is making room for a more intelligent, structured approach. Vectorless RAG with page index represents a profound paradigm shift. By leveraging document structure and explicit LLM reasoning rather than expensive vector databases, businesses can unlock higher accuracy and perfect explainability.
If you are dealing with complex legal filings, financial reports, or technical manuals in 2026, it is time to stop chunking and start indexing.
Here are the research links you can use:
1. Vectorless RAG & PageIndex Frameworks
- Infosys Engineering Blog: Vectorless RAG – The Next Evolution in Retrieval-Augmented Generation
- Medium (Technical Walkthrough): How PageIndex Works: A Step-by-Step Technical Walkthrough
- GeeksForGeeks: Vectorless RAG: PageIndex Architecture
2. Hierarchical & Tree-Based Document Retrieval (The Science behind it)
- Emergent Mind (Research Aggregator): Hierarchical RAG: Multi-level Retrieval Concepts
- Stanford/OpenReview AI Paper: RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (This is the foundational research paper that proved tree-based LLM reasoning beats standard vector chunking).
1 thought on “Vectorless RAG with Page Index: The Future of Document Intelligence in 2026”